

Design Is Why April’s Oracle ACE Adventure Was the Perfect Start to an Amazing Week
Being a part of the Oracle ACE program has been one of the most rewarding experiences I’ve had in my professional career. As a community, we’re passionate about technology in general, and Oracle’s specifically, and how we can share what we’ve learned and give back to our community. However, one of the best aspects of the program is that it recognizes that personal growth is not limited to a singular realm or outlook.

Lessons Learned from Entering the 3rd Annual ODTUG/AnDOUC Oracle Analytics Storytelling Challenge
For the past several years, ODTUG has hosted a competition where developers are given the same data set and asked to prepare a “data story” told through visualizations using Oracle Analytics Cloud. This year’s data

Schema-level Privileges Simplify Grants in Oracle Database
With Oracle database 23C, we finally have the ability to GRANT SELECT ANY TABLE on SCHEMA. When I was originally introduced to multiple schemas in the Oracle database, I was baffled by why DBAs seemed
Thoughts on Oracle Analytics from the Association of Institutional Research
Here I am in Cleveland, Ohio surrounded by more than a thousand professionals from the world of higher education who are PASSIONATE about analytics. This is the world of universities and colleges and those who
Jan 25, 2023 – Upgrading from OBIEE to Oracle Analytics
Join us on January 25, 2023 at 1:00 PM CT for a webinar on Upgrading from Oracle Business Intelligence Enterprise Edition (OBIEE) to Oracle Analytics. Have you heard about the new Oracle Analytics platform, but

Euler and Christmas Lights
I have always enjoyed decorating my home with Christmas lights. I think I enjoy the planning process even more than actually stringing the lights. I recently moved into a new house with a truss over
Alternative Color Strategies for the New Redwood Theme in OAC
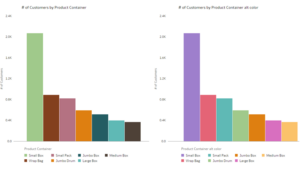
The introduction of the Redwood theme in Oracle Analytics represents the culmination of Oracle’s long-term, serious commitment to leading practices in user interface design. Redwood introduces a unified look and feel across all Oracle products

Governed vs. Self-Service Analytics Blog Featured on Oracle Site
Have you ever played tug-of-war? If you have, then you are familiar with the tension of the rope as you grip it tightly in your hands, trying to avoid rope burn. You and your team

Which BI Dashboards Are Most Valuable?
Not all business intelligence dashboards and analytics projects are worth the same. Some are viewed by hundreds of employees, while others are highly specific and meant to be used by only a few people. Likewise,
